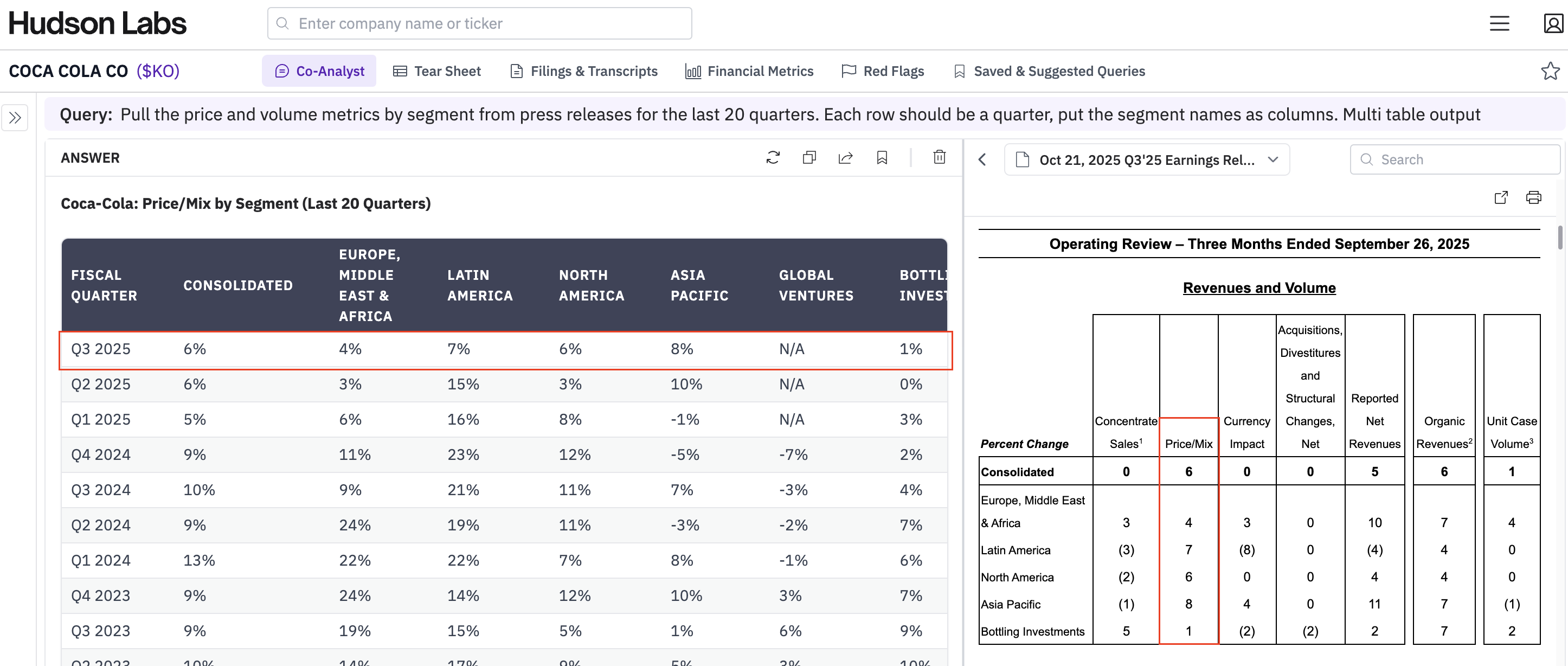
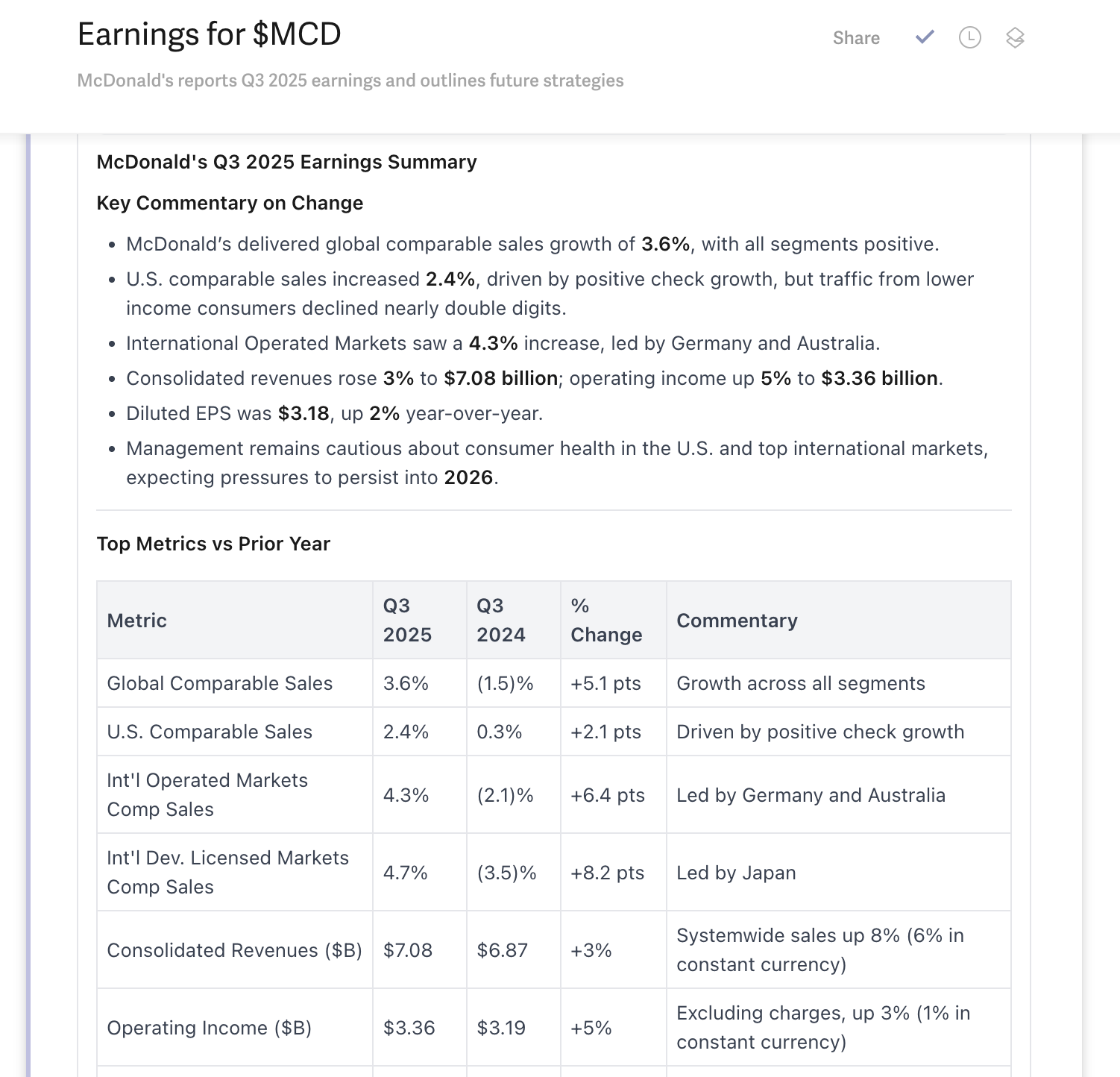
Notes from an information session with Suhas Pai, author of Designing Large Language Model Applications and Co-Founder of Hudson Labs
DeepSeek R1: Advancing AI Efficiency and Accuracy
Over 13 months, DeepSeek has developed an AI system that is powerful, efficient, and adaptable. It handles tasks from code generation to mathematical problem-solving.
1. Optimized AI with Mixture of Experts
DeepSeek employs a Mixture of Experts (MoE) architecture , activating only necessary parameters for each task. Instead of engaging the entire model, it assigns specialized experts for specific tasks e.g. mathematics, improving efficiency.
For example, DeepSeek’s 16-billion-parameter model uses only 2.4 billion parameters at a time, maintaining performance while reducing computational cost. This selective activation minimizes waste, much like lighting only the needed section of a library rather than the entire building.
Fun fact: Hudson Labs was involved in the creation of one of the first publicly available MoE models as part of the M*DEL project.
2. Enhanced Reasoning and Self-Correction
DeepSeek’s R1 model incorporates self-correction, allowing it to review and refine its outputs. This feature improves accuracy in complex tasks such as mathematical proofs and code generation.
The model also tokenizes numbers into individual digits (e.g., “123” → “1,” “2,” “3”), enhancing its mathematical reasoning. Additionally, DeepSeek curates training data to reduce redundancy, ensuring the AI learns to reason rather than memorize.
3. Reducing Costs Without Sacrificing Performance
AI models can be expensive to run, but DeepSeek minimizes costs by using dozens of optimization tricks MoE’s sparse activation reduces inference costs by 70% compared to dense models of similar capability. The lower labor, infrastructure, and electricity costs also help.
How to Improve DeepSeek Responses with Better Prompts
Well-structured prompts lead to better AI responses. Instructions specifying verifiable criteria for good responses encourage systematic reasoning. Hudson Labs’ CTO Suhas Pai has also experimented with using Mandarin inputs and English outputs, leveraging Mandarin’s conciseness for efficiency. The results are promising but inconclusive and an interesting area of study.
Next Steps
Challenges remain, including skepticism about China-hosted AI. Serving the DeepSeek-R1 671B model at low latencies is also technically challenging.